▶ 하이퍼파라미터 (HyperParameter)
- 모델 파라미터 : 머신러닝 모델이 학습하는 파라미터
- 파라미터(매개변수) : 학습 과정에서 생성되는 변수
- 하이퍼파라미터 : 머신러닝 모델이 학습할 수 없어서 사용자가 지정해야만 하는 파라미터
→ 각 층의 뉴런 수, 배치 사이즈, 매개변수 갱신 시의 학습률과 가중치 감소 등.. - 가장 우수한 성능을 보이는 모델의 하이퍼파라미터를 선정하기 위해 그리드 서치(Grid Search) 사용
▶ 검증 Data Set
- 데이터 세트를 훈련 - 검증 - 테스트 세트로 나누어 훈련 또는 테스트 세트에 과적합한 모델이 될
가능성능 낮출 수 있음 (60 / 20 / 20%) - 하이퍼파라미터의 성능을 평가 할 때, 시험 데이터 셋을 이용하면 안된다.
→ 시험 데이터로 하이퍼파라미터 튜닝 시, 값이 시험 데이터에 오버피팅 되기 때문 - 하이퍼파라미터 전용 성능 검증 데이터 즉, 하이퍼파라미터 조정용 데이터 Set을 검증 데이터라고 부른다.
ⓐ 훈련 데이터 : 매개변수 학습
ⓑ 검증 데이터 : 하이퍼파라미터 성능 평가
ⓒ 시험 데이터 : 신경망의 범용 성능 평가

(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
x_train, t_train = shuffle_dataset(x_train, t_train)
val_rate = 0.2
val_num = int(x_train.shape[0] * val_rate)
print(val_num)
# 검증 Data Set x_train shape 60000 중 20% 추출하여 12,000개 검증 Data Set 선정
def shuffle_dataset(x, t):
"""데이터셋을 뒤섞는다.
----------
x : 훈련 데이터
t : 정답 레이블
Returns
-------
x, t : 뒤섞은 훈련 데이터와 정답 레이블
"""
permutation = np.random.permutation(x.shape[0])
x = x[permutation,:] if x.ndim == 2 else x[permutation,:,:,:]
t = t[permutation]
return x, t검증 세트 사용 방법
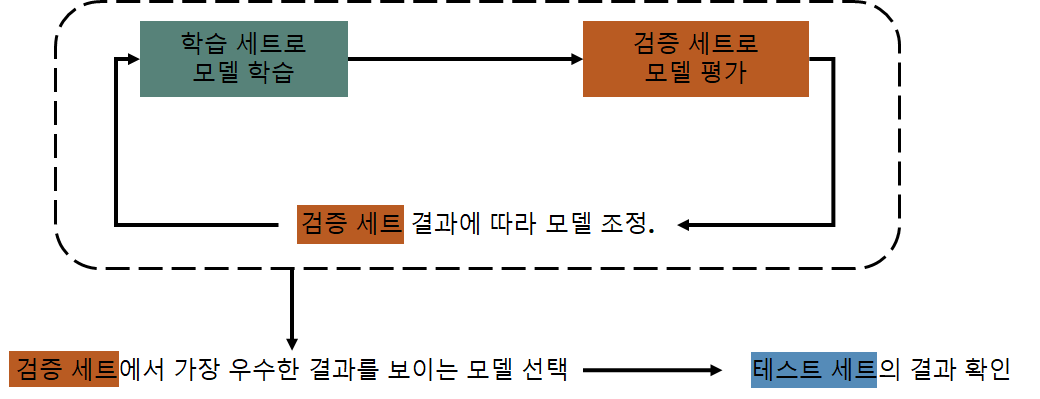
- 학습 세트를 통해 학습된 모델을 바로 테스트 세트로 결과를 얻는 것이 아닌, 검증 세트를 사용하여 학습 세트의 결과를 평가함.
- 검증 세트의 결과에 따라 모델을 조정하여 가장 우수한 결과를 보이는 모델을 선택한 후, 이 모델을 테스트 세트를
사용하여 다시 평가함.
▶ 교차 검증 (Cross Validation)
- 검증 세트를 사용하면 test set에 과적합(overfitting)되어 다른 실제 데이터를 가지고 예측 수행시 결과가 엉망임.
- 고정된 test set을 가지고 모델의 성능확인 후 파라미터 수정하는 과정을 반복하기에 결국 test set에만 잘 동작하는 모델이 되는 것.
- 고정된 test set == test set이 데이터 중 일부분으로 고정되어 있음.
-
- 이를 해결하고자 하는 것이 교차 검증(cross validation)
- 교차 검증 사용 시 안정적인 검증 점수를 얻을 수 있고, 훈련에 더 많은 데이터 사용가능함.
- 교차 검증은 검증 세트를 떼어 내어 평가하는 과정을 여러 번 반복함.

- 전체 데이터 셋을 k개의 subset으로 나누고 k번의 평가 실행
- 이 때 test set을 중복 없이 바꾸어가면서 평가를 진행함.
- 모델의 각 평가 점수를 평균하여 최종 검증 점수를 얻음.
- k-폴드 교차 검증 (k-fold cross validation)
- 훈련 세트를 k 부분으로 나눠서 교차 검증을 수행하는 것.
- 이를 해결하고자 하는 것이 교차 검증(cross validation)
▶ 하이퍼파라미터 최적화
- 하이퍼파라미터를 최적화 할 때의 핵심은 하이퍼파라미터의 최적 값이 존재하는 범위를 줄여가면서 대략적인
범위를 설정하고 그 범위에서 무작위로 하이퍼파라미터 값을 골라낸 후, 그 값 기준으로 정확도를 평가 - 위 작업을 반복하여 하이퍼파라미터의 최적 값의 범위를 좁혀 가는 것
- 신경망 하이퍼파라미터 최적화에서는 그리드 서치같은 규칙적인 탐색보다 무작위로 샘플링 하는 편이 더 좋음
→ 실제 0.001 ~ 1,000 사이와 같이 10의 거듭제곤 단위로 범위를 지정하며 이를 "로그 스케일"이라 한다.
▶ 최적화 순서
①단계, 하이퍼파라미터 값의 범위를 설정
②단계, 설정된 범위에서 하이퍼파라미터의 값을 무작위로 추출
③단계, 2단계에서 샘플링한 하이퍼파라미터 값을 사용하여 학습하고, 검증 데이터로 정확도를 평가 (에폭 작게 설정)
④단계, 2-3단계를 지정 횟수만큼 반복하여, 정확도의 결과를 보고 하이퍼파라미터의 범위를 좁힙니다.
# 정리
1. 매개변수 갱신 방법에는 확률적 경사 하강법(SGD)외 모멘텀, AdaGrad, Adam 등이 있다.
2. 가중치의 초깃값으로는 "Xavier 초깃값과 He 초깃값" 이 효과적이다
3. 배치 정규화를 이용하면 학습 속도가 향상되고, 가중치 초깃값에 대한 의존도가 낮다.
4. 오버피팅을 억제하는 정규화 기술은 가중치 감소와 드롭아웃이 있다.
5. 하이퍼파라미터 값 탐색은 최적 값이 존재할 법한 범위를 점차 좁히면서 하는 것이 효과적이다.
'Deep Learning > 밑바닥부터 시작하는 딥러닝' 카테고리의 다른 글
| DL - #7, Pooling 계층 구현 (0) | 2022.02.28 |
|---|---|
| DL - #7, CNN 계층 구현 (0) | 2022.02.28 |
| DL - #6, Batch Normalization (0) | 2022.02.14 |
| DL - #6, 가중치의 초깃값 (0) | 2022.02.14 |
| DL - #5-2, 활성화 함수 계층 구현 (0) | 2022.02.04 |