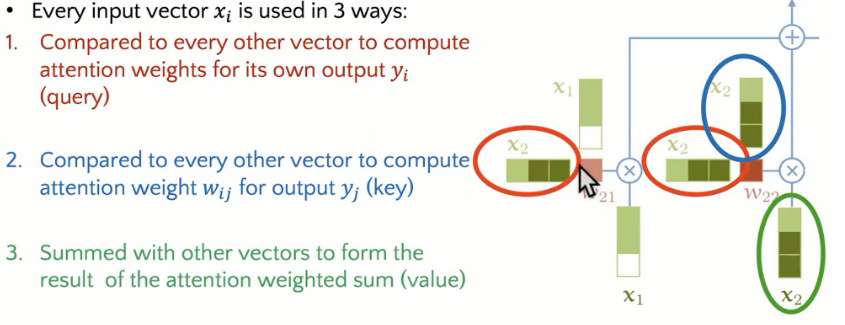
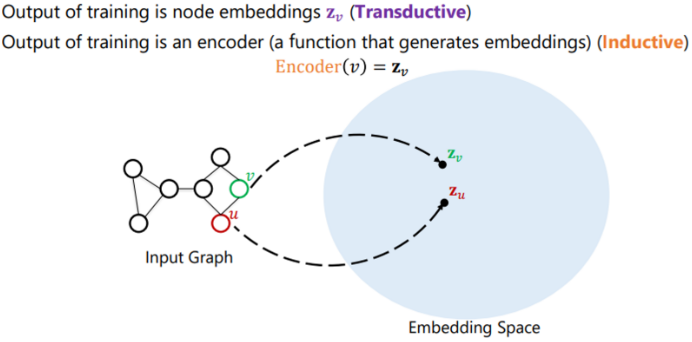
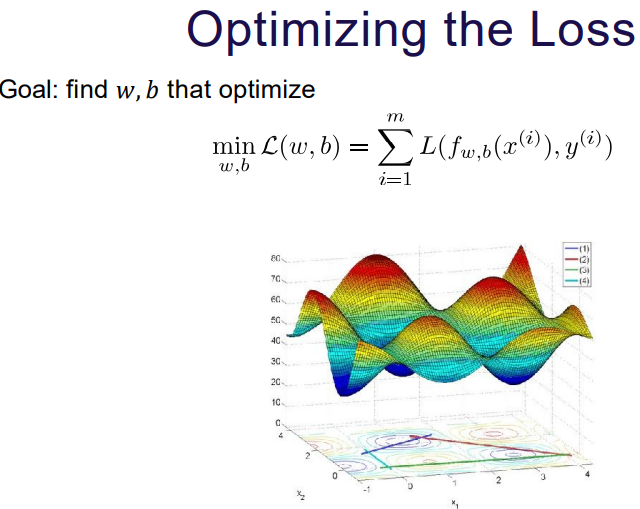
[해외 논문 리뷰] 메모, Tip
📌 타이틀은 핵심을 포착하라! - Abstract 논문의 주제와 가장 중요한 결과 혹은 발견을 간략하게 포함시켜 독자가 한 눈에 어떤 내용인지 파악 하게 작성📌 '소개'란에는 문제의 배경을 명확히! - Introduction 왜 이 문제가 중요한지, 어떤 도전과제들이 있었는지 간략하게 소개 (핵심적인 방법린 및 알고리즘)📌 '관련 연구'란에서는 다양성을! - Related works 여러 논문들의 주요 아이디어와 장단점을 간략하게 비교하며, 리뷰하는 논문이 어디에 위치하는지 티스토리 독자들에게 명확하게 작성📌 '방법론'란에서는 그림을 활용하자! - Method 복잡한 알고리즘, 구조 등은 그림, 플로우차트, 그림 설명 등을 활용해서 간단하게 표현해 주세요. 그림 하나가 긴 설명을 대체 가능하게...📌 '..