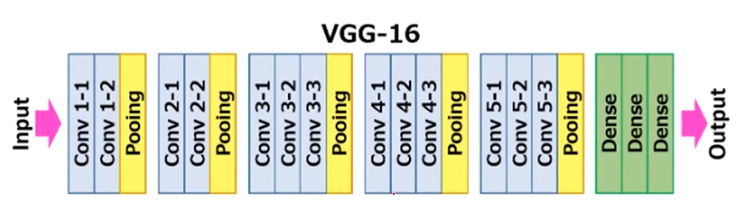
💡Network (아키텍처 구조) EfficientNet Network는 메인으로 mobile inverted bottleneck convolution(MBConv) block을 사용한다. MBConv block Depthwise separable conv와 Squeeze-and-excitation(se) 개념을 적용한 방식이다. 📝 https://github.com/qubvel/efficientnet GitHub - qubvel/efficientnet: Implementation of EfficientNet model. Keras and TensorFlow Keras. Implementation of EfficientNet model. Keras and TensorFlow Keras. - GitHub ..