✍
제가 직접 논문 전체를 해석 할 능력이 안 되서,,,논문 정리가 잘 되어 있는 다수의 블로그들을
보고 공부하여 내용 정리 및 코드 구현을 해보려고 합니다.
✍ R-CNN 논문
Rich feature hierarchies for accurate object detection and semantic segmentation Tech report (v5)
https://arxiv.org/pdf/1311.2524.pdf
👉 논문 정리

- 12년 Image Classification Challenge에서 AlexNet이 큰 성공을 하게 되며, Object Detection에도 CNN이 적용 된 모델을 연구하게 되는데, 그 첫 번째 결과물이 R-CNN이다.
- R-CNN은 region Proposals와 CNN을 결합한 모델이며, R-CNN 이전에 Sliding Window Detection에 CNN을 적용한
OverFeat Model이 존재한다. - R-CNN이 수행하는 Object Detection을 수행하는 알고리즘 방식은 아래와 같다.
1) 입력 이미지에 Selective Search 알고리즘을 적용하여 bounding box(Region Proposal) 2,000개 추출
2) 추출된 bounding box를 227 x 227 Size로 Resize(warp) 하며, 이 때 박스의 비율 등은 고려하지 않는다.
3) Fine tunning 되어 있는 Pre-trained CNN을 통과 시켜, bounding box의 4096차원의 특징 벡터를 추출
4) 추출된 벡터를 가지고 각각의 클래스(Object의 종류) 마다 학습시켜놓은 SVM Classifier를 통과하여 분류한다.
5) bounding box regression을 적용하여 bounding box의 위치를 조정한다.
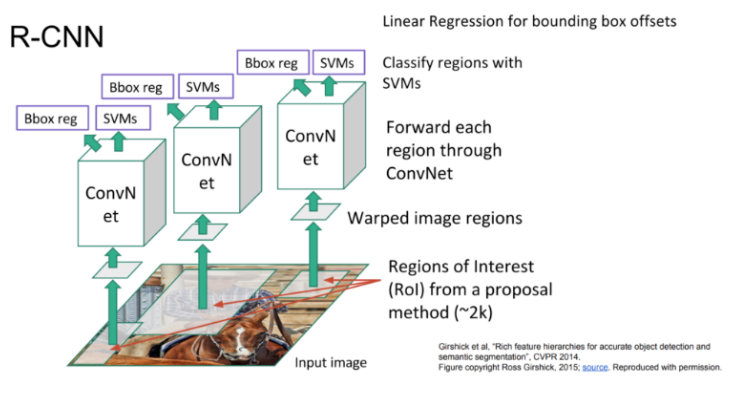
👉 R-CNN의 구성
R-CNN은 3개의 module(region proposal, CNN, SVM classifier)로 이루어져 있습니다.
각각의 module이 어떤 역할을 수행하는지 살펴보겠습니다.
(1) region proposal
selective search 기법을 사용해서 이미지에서 object의 위치를 추출합니다.
selective search는 다음과 같은 프로세스로 이루어집니다.
1. 이미지의 초기 세그먼트를 정하여, 수많은 region 영역을 생성
2. greedy 알고리즘을 이용하여 각 region을 기준으로 주변의 유사한 영역을 결합
3. 결합되어 커진 region을 최종 region proposal로 제안
이미지에 selective search를 적용하면 2000개의 region proposal이 생성되는데, 이들을 CNN의 입력 사이즈(227x227)로 warp(resize) 하여 CNN에 입력합니다. 논문에서는 warp 과정에서 object 주변 16 픽셀도 포함하여 성능을 높였다고 합니다.
(2) CNN
CNN은 5개의 convulutional layer와 2개의 FC layer를 가진 AlexNet 형태를 사용했습니다. R-CNN은 soft-max layer 대신에 SVM을 사용하기 때문에 2개의 FC layer가 존재합니다.
ILSVRC 2012 데이터 셋으로 미리 학습된 pre-trained CNN 모델을 사용했으며, Object detection을 적용할 dataset으로 fine-tunning 했습니다.
아래는 fine-tunning을 적용한 후와 적용하지 않았을 때의 성능입니다.
1~3 행은 fine-tunning을 적용하지 않았고, 4~6행은 fine-tunning을 적용한 것입니다.
성능이 높아진 것을 확인할 수 있습니다.

(3) SVM classifier
CNN으로 추출한 4096 차원의 특징 벡터를 SVM으로 분류합니다.
- bounding box regression
R-CNN에서는 SVM으로 분류된 bounding box에 bounding box regression을 적용해 주었습니다.
아래 표는 bounding box regression이 적용된 것과 적용되지 않은 것의 성능차이를 나타낸 표 입니다.
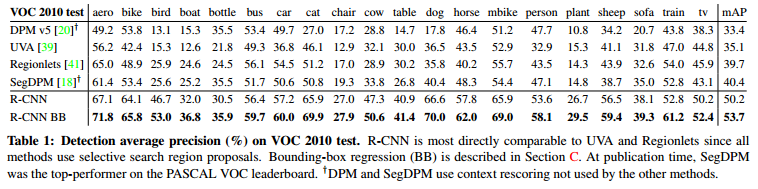
성능이 좋아진 것을 확인할 수 있습니다.
bounding box regression이 무엇인지 살펴보겠습니다.
bounding box regression는 SVM을 통해 분류된 bounding box를 ground-truth box와 비슷하게 조정해주는 역할을 합니다. 또한, selective search로 검출된 2000개의 bounding box에 모두 적용하는 것이 아니라, ground-truth box와 IoU(Intersection over Union)가 가장 높은 bounding box를 선택하여 bounding box regression을 적용합니다.
👉 R-CNN 한계
→ R-CNN 모델은 동시대 객체 탐지 모델에 비해 성능이 매우 뛰어 났으며, Object Detection을 수행하기 위해
딥러닝을 최초로 적용 했다는 큰 성과를 낸 모델
(그러나, R-CNN 모델 자체가 매우 복잡하고 느리다는 단점이 존재)
→ 1개의 Input Image가 Selective Search를 통과하여 2,000개의 이미지를 출력하여 Infrence를 진행하기 때문에 Application에 적용하기엔 너무 느리다는 단점이 있다. (약 GPU 13초, CPU 54초 소요)
(R-CNN의 단점을 극복하기 위해 Fast R-CNN, Faster R-CNN 등 다양한 모델 등장)
👉 Source Code
👀 Reference
-. R-CNN 'Rich feature hierarchies for accurate object detection and semantic segmentation'
-. inflearn 딥러닝 완벽 가이드 강의 / 권철민 강사님
-. 딥러닝 공부방 / AI 꿈나무님 블로그